
Johann Lee
Recent Interests
- Agriculture, real estate, and elderly care
- VLA models & Emodied AI
Publications
-
 ICLR
ICLR 2026 (International Conference on Learning Representations)
ICLR
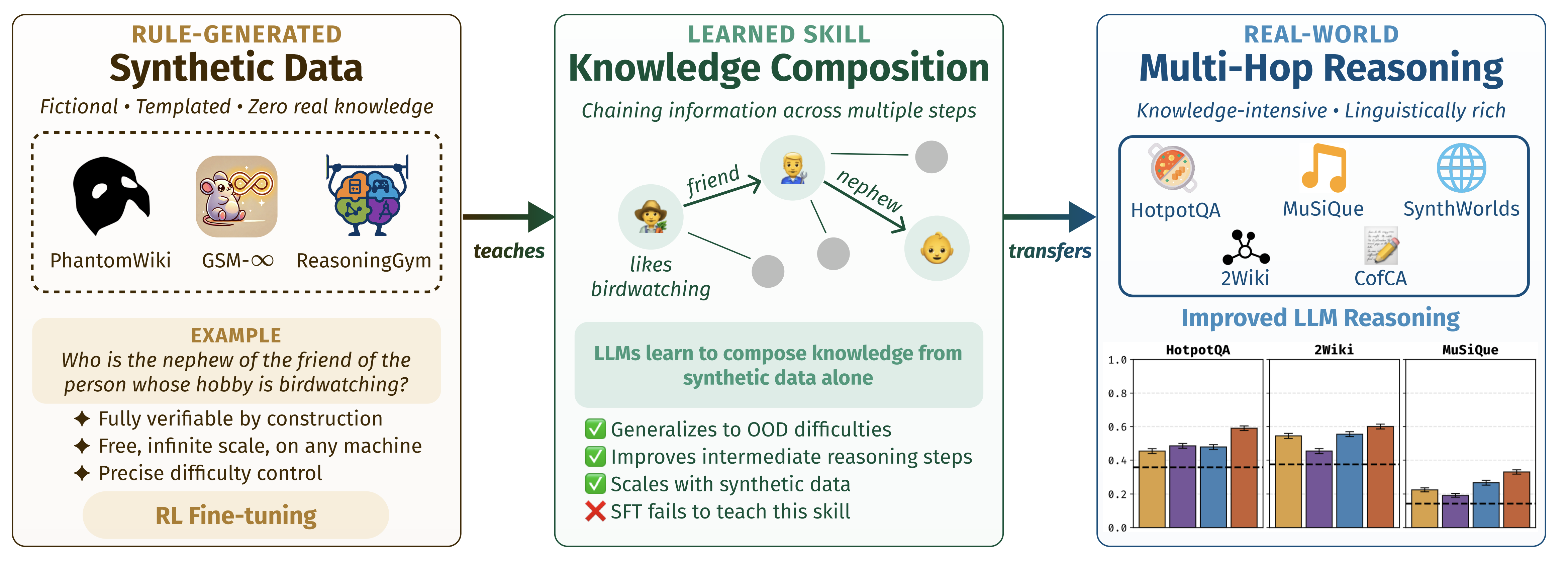
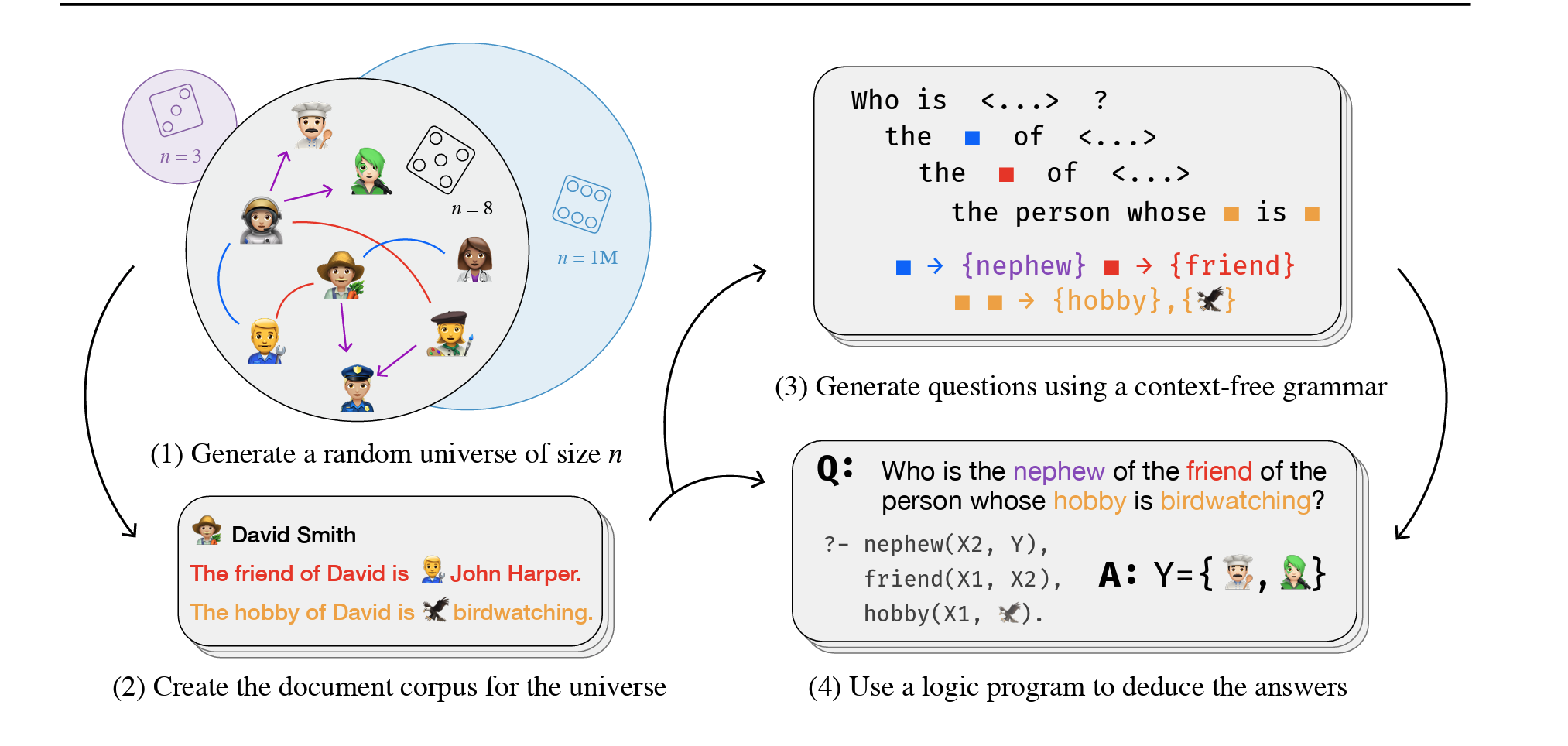
ICLR 2026 (International Conference on Learning Representations)RL post-training has considerable limitations: human-annotated datasets are expensive, and LLM-generated data lacks reliable verification. We show that RL fine-tuning on rule-generated synthetic data can induce knowledge composition. This skill transfers to real-world question-answering benchmarks, significantly improving performance for reasoning across multiple logical steps.
-
 ICML
ICML 2025 (International Conference on Machine Learning)
ICML
ICML 2025 (International Conference on Machine Learning)We adresses evaluation datasets getting scraped into pretraining data with a pipeline for generating synthetic datasets (for reasoning and retrieval evaluation). We demonstrate its scraping resilience, and use it to identify improvements in RAG and agentic methods: subtask composition, multi-branch reasoning, and needle-in-a-haystack retrieval.
-
 Stanford GRACE Journal Vol. 3 No. 1 (2025): Generative AI and Global FuturesTop 0.5% of 3000+ submissions
Stanford GRACE Journal Vol. 3 No. 1 (2025): Generative AI and Global FuturesTop 0.5% of 3000+ submissionsSince initiatives for measuring safe, ethical AI are scattered and fragmented, this review outlines state-of-the-art methods, their proper utilization, and systemic weaknesses and scaling issues. By doing so, we seek to foster continuing discourse and innovation among both technical developers and non-technical policymakers.